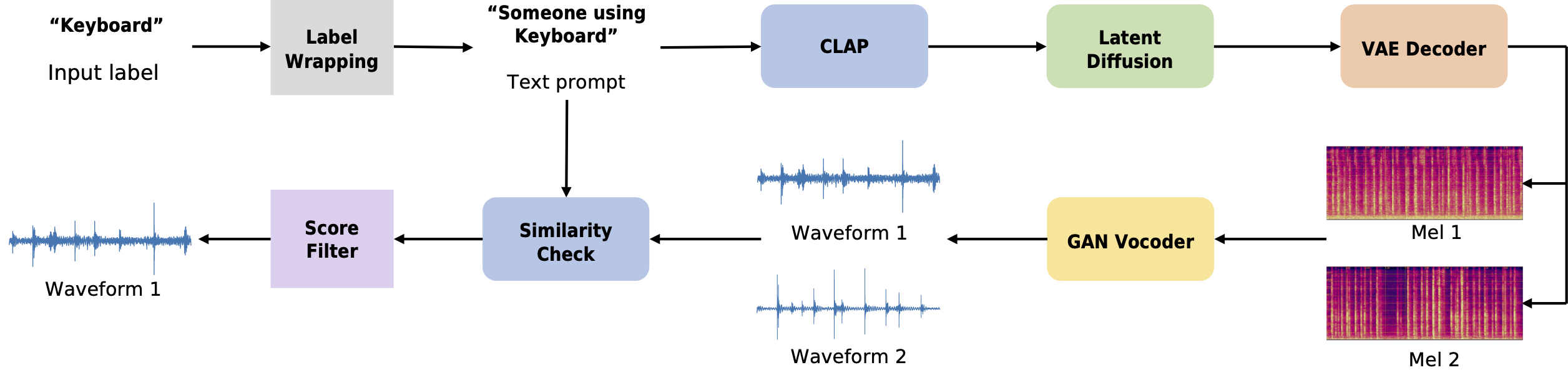
Foley sound generation system
Our proposed system is based on the widely used structure on sound generation, which consists of an encoder, a generator, a decoder and a vocoder. Instead of directly using labels as the input, we employ a wrapping strategy to generate text descriptions for each label as the initial input for the system, such as text: “someone using keyboard”, for label: “3, keyboard”. Then a trainable embedding is concatenated into this input embedding with LDM loss as a guide to seek the most suitable embedding of each sound. During the sampling stage, the system takes the text embedding from CLAP as the condition and utilizes the LDM model to generate the intermediate value of the sound feature in tokens. Subsequently, the mel-spectrogram-result can be decoded from the tokens by the VAE decoder and reconstructed into waveform by the GAN vocoder.